Voice AI 현지화 품질, 번역이 아니라 운영 게이트입니다

Voice AI를 한국어 상담에 붙일 때 가장 위험한 오해는 “모델이 한국어를 지원하면 충분하다”는 생각입니다. 실제 운영 품질은 STT 정확도 하나가 아니라 숫자·띄어쓰기·금칙어·상담원 이관·CRM 기록이 한 흐름 안에서 관리되는지로 결정됩니다.
Deepgram은 2026년 5월 21일 changelog에서 multilingual model 전반의 profanity filtering 지원과 Korean spacing improvements를 공지했고, 2026년 6월 11일에는 self-hosted release를 별도로 공지했습니다. 이 변화는 단순 기능 업데이트가 아니라, 한국/APAC 기업이 Voice AI를 구매할 때 확인해야 할 품질 게이트가 더 명확해졌다는 신호입니다.
한국어 상담 품질은 “언어 지원”보다 좁게 봐야 합니다
한국어 콜센터에서는 같은 문장도 띄어쓰기, 숫자 읽기, 욕설·민원 표현, 존댓말 뉘앙스에 따라 후속 처리 결과가 달라집니다. 예를 들어 “십오만원”과 “15만 원”, “환불 안 됐어요”와 “환불이 안됐어요”는 사람에게는 거의 같지만, 규칙 기반 라우팅·CRM 검색·QA 리포트에서는 다른 입력으로 취급될 수 있습니다.
한국어 지원 여부는 체크박스입니다. 운영 품질은 “그 한국어가 어떤 시스템 기록으로 남는가”에서 갈립니다.
따라서 현지화 품질은 번역팀의 문장 검수만으로 끝나지 않습니다. 상담 흐름 전체에서 아래 4가지를 같이 봐야 합니다.
- STT가 고객 발화를 어느 정도 안정적으로 구조화하는가
- 욕설·위협·민감 표현을 어떤 정책으로 감지하고 처리하는가
- 실패·분노·불확실 상황에서 상담원에게 언제 이관하는가
- 통화 후 CRM·QA·재응대 데이터가 검색 가능한 형태로 남는가
품질 게이트는 모델 앞뒤에 놓입니다
Voice AI 운영에서 LLM은 가운데 한 조각입니다. 고객 경험을 망치는 지점은 오히려 LLM 바깥에서 자주 발생합니다. 숫자가 잘못 정규화되면 약속 시간이 틀어지고, 욕설 감지가 빠지면 상담원 이관 타이밍이 늦어지며, CRM 메모가 비정형으로 남으면 다음 접점에서 고객은 같은 설명을 반복해야 합니다.
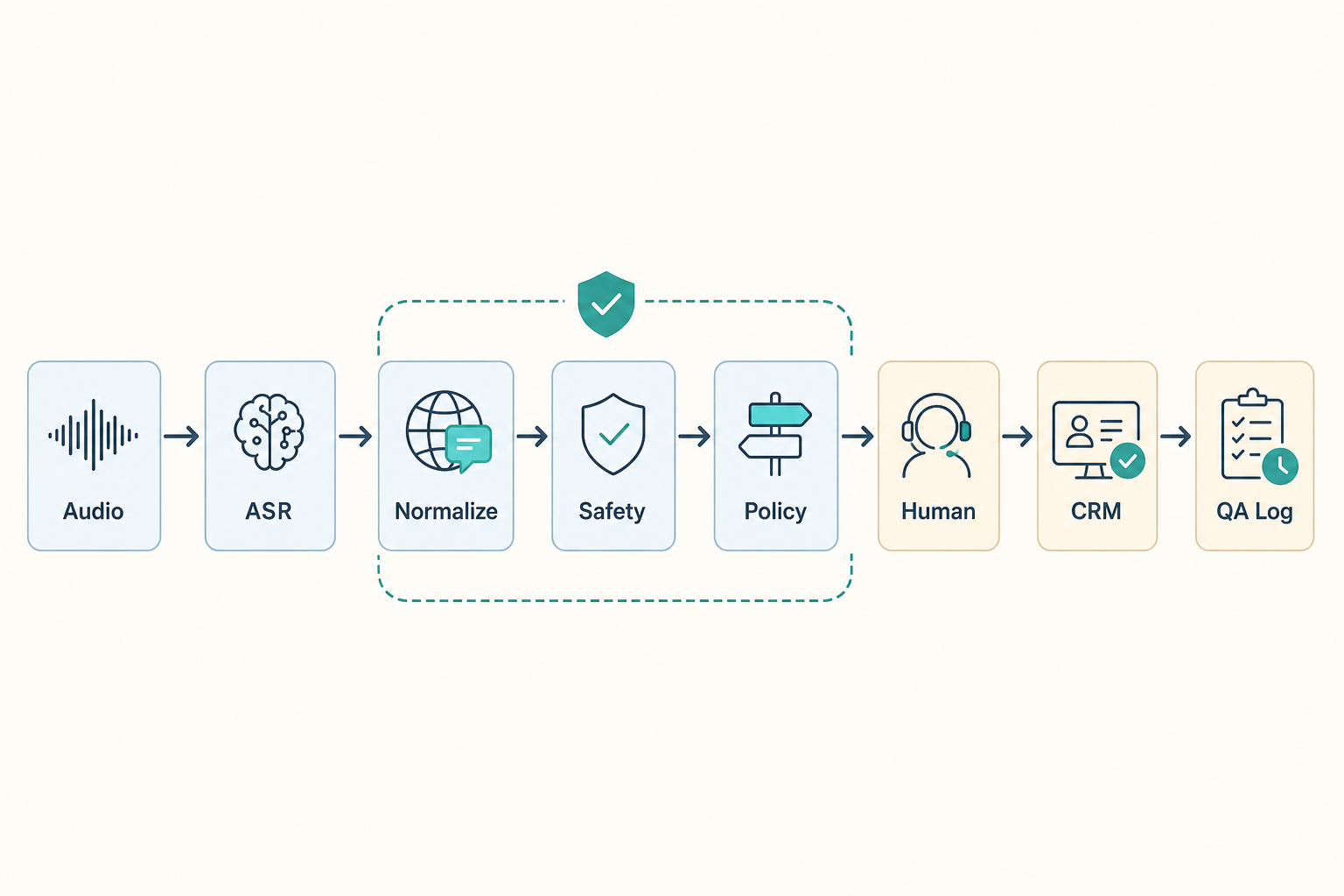
운영팀은 모델 선택 전에 다음 게이트를 정의해야 합니다.
- 입력 게이트: STT, 숫자·주소·이름 정규화, 한국어 띄어쓰기 보정
- 안전 게이트: profanity, 위협, 민감정보, 미성년자·취약고객 신호 감지
- 정책 게이트: 자동 응답 지속, 상담원 이관, 콜백 예약, 종료 기준
- 기록 게이트: CRM 필드, QA 태그, 재응대 reason code, 감사 로그
Localization QA checklist
- Language: ko-KR, dialect/spacing/numerals tested
- Safety: profanity + threat + PII policy mapped
- Handoff: escalation reason stored before transfer
- CRM: searchable summary + next action written
- Review: failed-call samples inspected weekly
이 체크리스트는 기술 문서가 아니라 구매·운영 문서에 들어가야 합니다. Voice AI가 실제 고객 접점에 들어가면, “모델이 알아들었는가”보다 “운영자가 통제 가능한가”가 더 중요해집니다.
Self-hosted와 필터링은 규제 산업의 구매 기준입니다
Deepgram의 2026년 6월 self-hosted release 공지는 규제 산업에서 중요한 맥락을 제공합니다. 금융, 보험, 의료, 공공 영역은 음성 데이터의 보관 위치, 접근 권한, 로그 보존 정책을 모델 성능만큼 중요하게 봅니다. 모든 기업이 self-hosted를 선택해야 한다는 뜻은 아니지만, 적어도 조달 질문지는 더 구체적이어야 합니다.
구매 단계에서 확인할 질문은 다음처럼 바뀝니다.
- 음성 원본과 transcript는 어디에 저장되는가?
- profanity·민감정보 감지는 실시간 경로에 있는가, 사후 분석에만 있는가?
- 한국어 띄어쓰기·숫자 정규화는 어떤 downstream system에 반영되는가?
- 상담원 이관 전후의 맥락은 CRM에 남는가?
- 감사 로그는 누가, 얼마나 오래, 어떤 권한으로 볼 수 있는가?
“한국어 된다”는 답변은 부족합니다. “한국어 상담이 통제 가능한 운영 데이터로 남는다”가 조달 기준이어야 합니다.
BringTalk 관점: 현지화는 LQA·FUA의 선행 조건입니다
BringTalk이 보는 LQA(Lead Qualification Automation)와 FUA(Follow-Up Automation)는 단순 자동 통화가 아닙니다. 첫 통화에서 고객 의도·거절 사유·다음 행동이 구조화되어야 후속 연락이 의미를 가집니다. 한국어 현지화 품질이 낮으면 FUA는 자동화가 아니라 잘못된 맥락의 반복 연락이 됩니다.
운영 설계는 다음 순서가 안전합니다.
- 샘플 통화 50~100건에서 자주 나오는 숫자·주소·금칙어·이관 사유를 모읍니다.
- STT/정규화/필터링 결과가 CRM 필드와 맞는지 확인합니다.
- 불확실도가 높은 발화는 자동 답변보다 확인 질문 또는 상담원 이관으로 설계합니다.
- 매주 실패 콜을 다시 보고 policy와 prompt를 함께 조정합니다.
내부 가격이나 ROI 수치를 넣지 않아도 이 기준은 충분히 강합니다. 엔터프라이즈 의사결정자는 “얼마나 똑똑한가”보다 “운영팀이 어디까지 제어할 수 있는가”를 보고 구매합니다.
다음 파일럿의 DoD를 바꿔야 합니다
다음 Voice AI 파일럿의 완료 조건은 “데모에서 자연스럽게 말한다”가 아니라 아래처럼 정의되어야 합니다.
- 한국어 숫자·고유명사·띄어쓰기 오류가 CRM 기록에 어떤 영향으로 남는지 검증
- profanity·민감표현 감지 시 자동 응답/상담원 이관 정책 확정
- 고객 불만·취소·환불 intent에 대한 안전한 fallback 확인
- 통화 후 summary, next action, reason code가 검색 가능한 구조로 저장
- 실패 샘플을 기준으로 주간 QA 회의에서 개선 항목을 닫음
Voice AI 현지화의 목표는 “한국어로 말하는 봇”이 아닙니다. 한국어 상담을 안전하게 기록·이관·재응대할 수 있는 운영 체계를 만드는 것입니다.
출처: Deepgram Changelog — “Profanity Filtering Now Supported for All Multilingual Models; Korean Spacing Improvements”(2026-05-21), “Deepgram Self-Hosted June 2026 Release (260611)”(2026-06-11). 참고: Deepgram Voice Agent docs, LiveKit Agents docs.


