Voice AI Localization Quality Is an Operating Gate, Not a Translation Task

The riskiest misconception in Korean Voice AI deployment is that language support equals localization quality. In production, quality is decided by the full operating path: speech recognition, numeral normalization, spacing, profanity filtering, escalation policy, CRM writeback, and QA review.
Deepgram’s changelog noted multilingual profanity filtering and Korean spacing improvements on May 21, 2026, and a separate self-hosted release on June 11, 2026. The practical signal for Korean and APAC enterprises is clear: localization has moved from copy review to an operating control.
Language Support Is Only the Starting Line
In Korean customer conversations, spacing, numerals, honorific nuance, and complaint language all affect downstream systems. “십오만원” and “150,000 won” may be equivalent to a human agent, but they can become different records in routing rules, CRM search, and QA dashboards.
Language support is a checkbox. Operating quality is determined by what the conversation becomes after it is transcribed, filtered, routed, and stored.
A localization review should therefore cover more than translation quality. It should test four layers together:
- whether ASR turns caller speech into stable structured text
- how profanity, threats, and sensitive expressions are detected
- when the system escalates to a human agent instead of continuing automation
- whether the post-call record remains searchable for CRM, QA, and follow-up
The Quality Gates Sit Around the Model
The LLM is only one component in a Voice AI stack. Customer experience often breaks outside the model: wrong numeral normalization changes appointments, missed profanity delays escalation, and unstructured CRM notes make customers repeat the same story on the next contact.
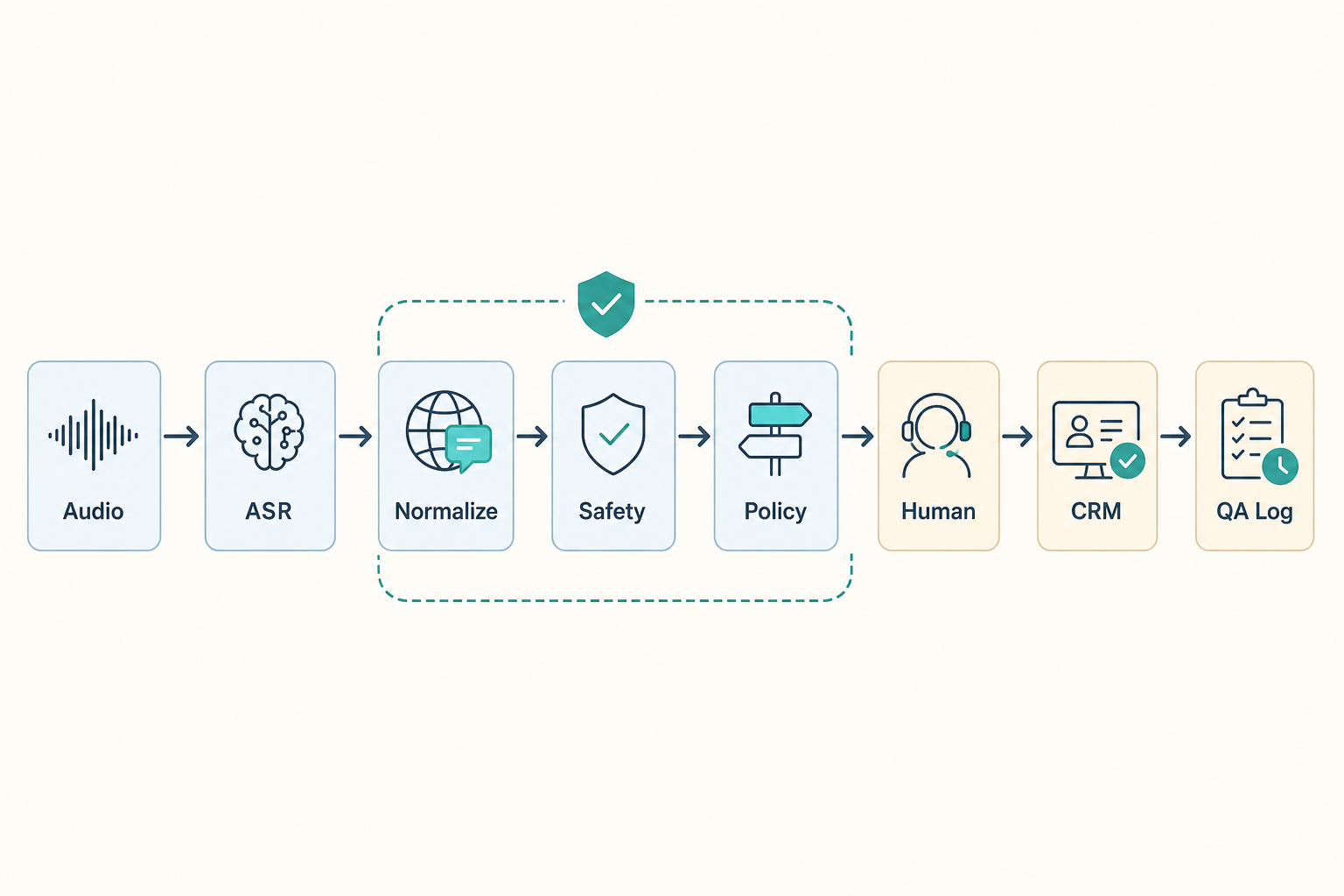
Enterprise teams should define these gates before selecting a model:
- Input gate: ASR, numerals, addresses, names, Korean spacing correction
- Safety gate: profanity, threats, sensitive data, vulnerable-customer signals
- Policy gate: continue automation, transfer to human, schedule callback, end call
- Record gate: CRM fields, QA tags, follow-up reason codes, audit logs
Localization QA checklist
- Language: ko-KR, dialect/spacing/numerals tested
- Safety: profanity + threat + PII policy mapped
- Handoff: escalation reason stored before transfer
- CRM: searchable summary + next action written
- Review: failed-call samples inspected weekly
This checklist belongs in the buying and operating plan, not only the engineering backlog. Once Voice AI touches real customers, “did the model understand?” matters less than “can the operating team control and audit the outcome?”
Self-Hosted and Filtering Are Procurement Criteria
Deepgram’s June 2026 self-hosted release also matters for regulated sectors. Finance, insurance, healthcare, and public-sector buyers care about data location, access control, and log retention as much as model accuracy. Not every deployment needs self-hosting, but every procurement process should ask sharper questions.
Useful questions include:
- Where are the audio file and transcript stored?
- Is profanity or sensitive-data detection applied in the real-time path or only after the call?
- How do Korean spacing and numeral normalization affect downstream systems?
- Is the handoff reason written to CRM before or after transfer?
- Who can access audit logs, and for how long?
“It supports Korean” is not enough. The procurement standard should be: Korean conversations become controllable operating data.
BringTalk POV: Localization Comes Before LQA and FUA
BringTalk’s LQA (Lead Qualification Automation) and FUA (Follow-Up Automation) depend on structured first-contact data. If the first call fails to capture intent, rejection reason, and next action, follow-up automation becomes repeated outreach with the wrong context.
A safer operating sequence is:
- Collect 50–100 sample calls and identify numerals, names, prohibited expressions, and common escalation reasons.
- Test whether ASR, normalization, and filtering outputs map cleanly to CRM fields.
- Route high-uncertainty utterances to confirmation questions or human handoff.
- Review failed calls weekly and tune policy, prompt, and workflow together.
This does not require publishing internal cost or ROI assumptions. Enterprise buyers can still make a decision from a clearer control question: how much of the customer interaction can operations inspect, route, and improve?
Change the Definition of Done for the Next Pilot
A Voice AI pilot should not be accepted because a demo conversation sounded natural. For Korean and APAC deployments, the definition of done should include:
- verification of how Korean numerals, names, and spacing errors affect CRM records
- a defined escalation policy for profanity, threats, refunds, and cancellations
- safe fallback behavior for complaint and high-risk intents
- searchable post-call summary, next action, and reason code fields
- a weekly QA loop that closes improvements against failed-call samples
The goal of localization is not a bot that speaks Korean. The goal is an operating system that can record, route, audit, and follow up on Korean conversations safely.
Sources: Deepgram Changelog — “Profanity Filtering Now Supported for All Multilingual Models; Korean Spacing Improvements”(2026-05-21), “Deepgram Self-Hosted June 2026 Release (260611)”(2026-06-11). Reference: Deepgram Voice Agent docs, LiveKit Agents docs.


